常用图表§
散点图§
import seaborn as sns import matplotlib.pyplot as plt df = sns.load_dataset('iris') sns.regplot(x=df["sepal_length"], y=df["sepal_width"]) plt.show()散点图,显示2个数值变量之间的关系。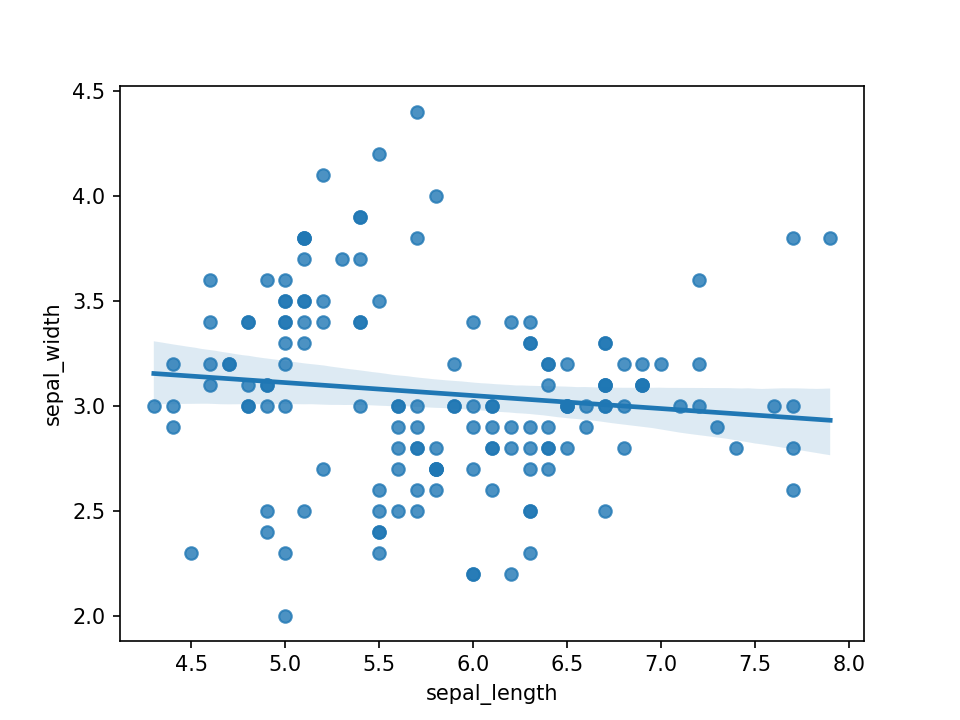
折线图§
import matplotlib.pyplot as plt import numpy as np values = np.cumsum(np.random.randn(1000, 1)) plt.plot(values) plt.show()折线图是最常见的图表类型之一。 将各个数据点标志连接起来的图表,用于展现数据的变化趋势。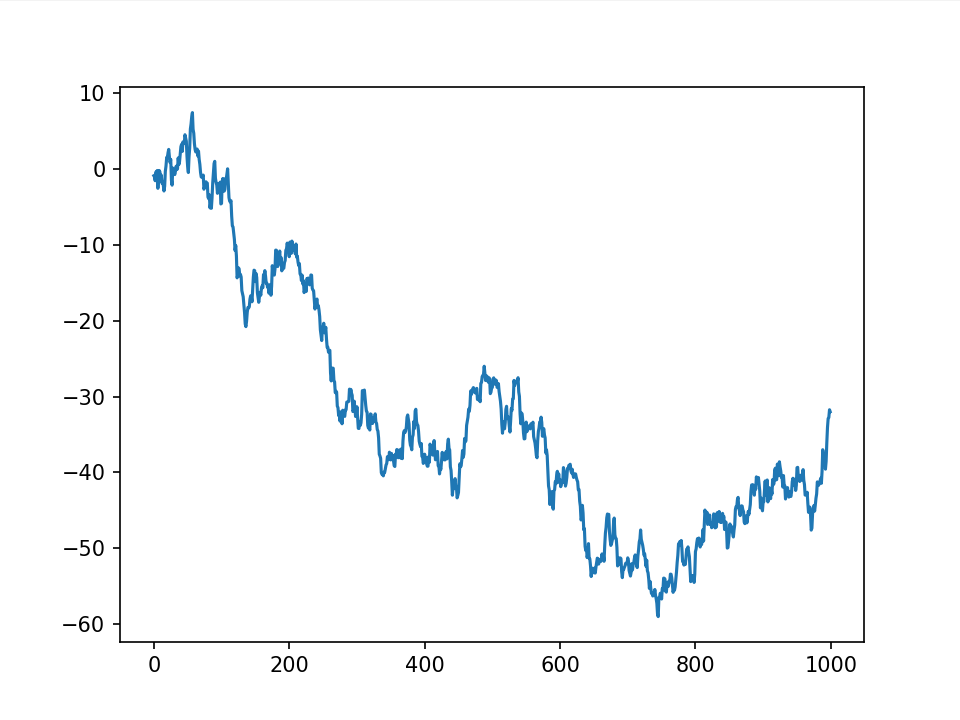
条形图§
import numpy as np import matplotlib.pyplot as plt height = [3, 12, 5, 18, 45] bars = ('A', 'B', 'C', 'D', 'E') y_pos = np.arange(len(bars)) plt.bar(y_pos, height) plt.xticks(y_pos, bars) plt.show()条形图表示多个明确的变量的数值关系。每个变量都为一个条形。条形的大小代表其数值。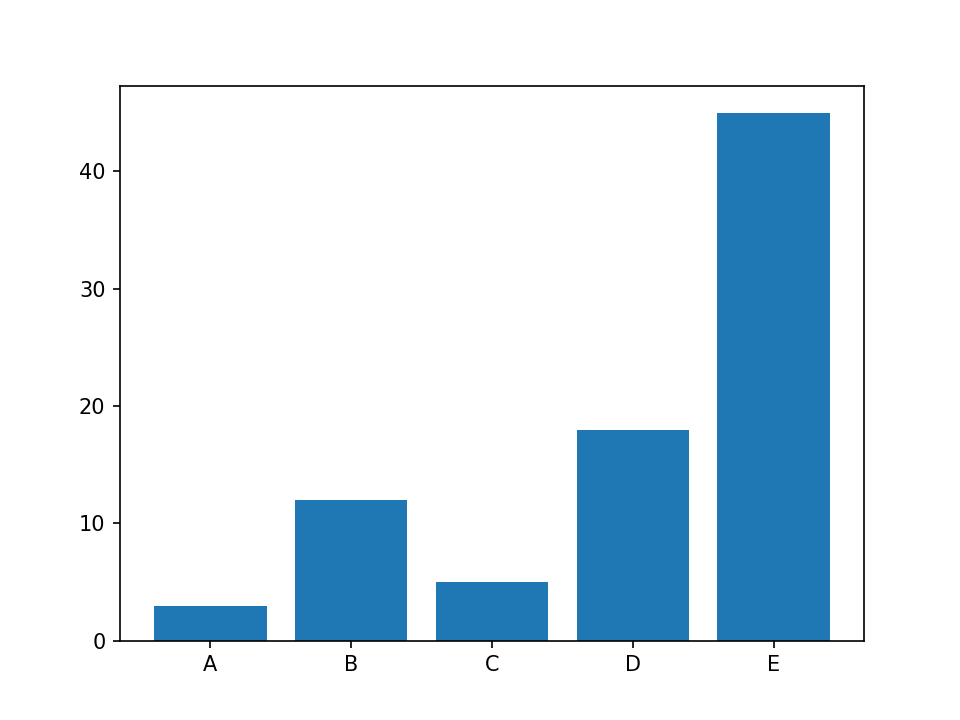
直方图§
import seaborn as sns import matplotlib.pyplot as plt df = sns.load_dataset('iris') sns.histplot(df, x="sepal_length", bins=20, kde=True, color="blue") plt.show()直方图,可视化一组或多组数据的分布情况。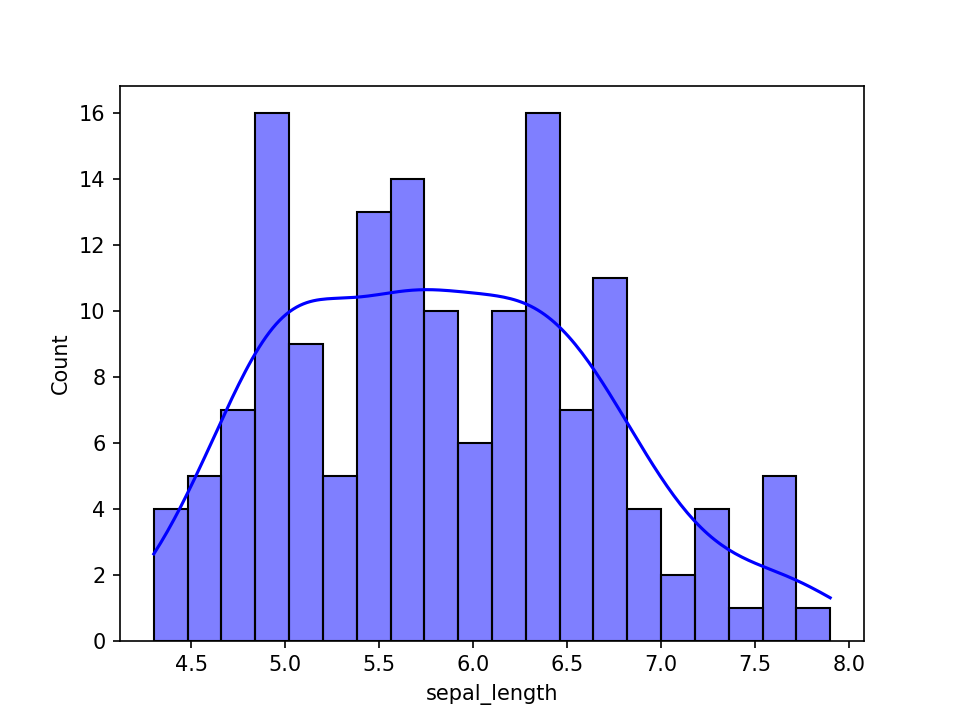
连接散点图§
import matplotlib.pyplot as plt import numpy as np import pandas as pd df = pd.DataFrame({'x_axis': range(1, 10), 'y_axis': np.random.randn(9) * 80 + range(1, 10)}) plt.plot('x_axis', 'y_axis', data=df, linestyle='-', marker='o') plt.show()连接散点图就是一个线图,其中每个数据点由圆形或任何类型的标记展示。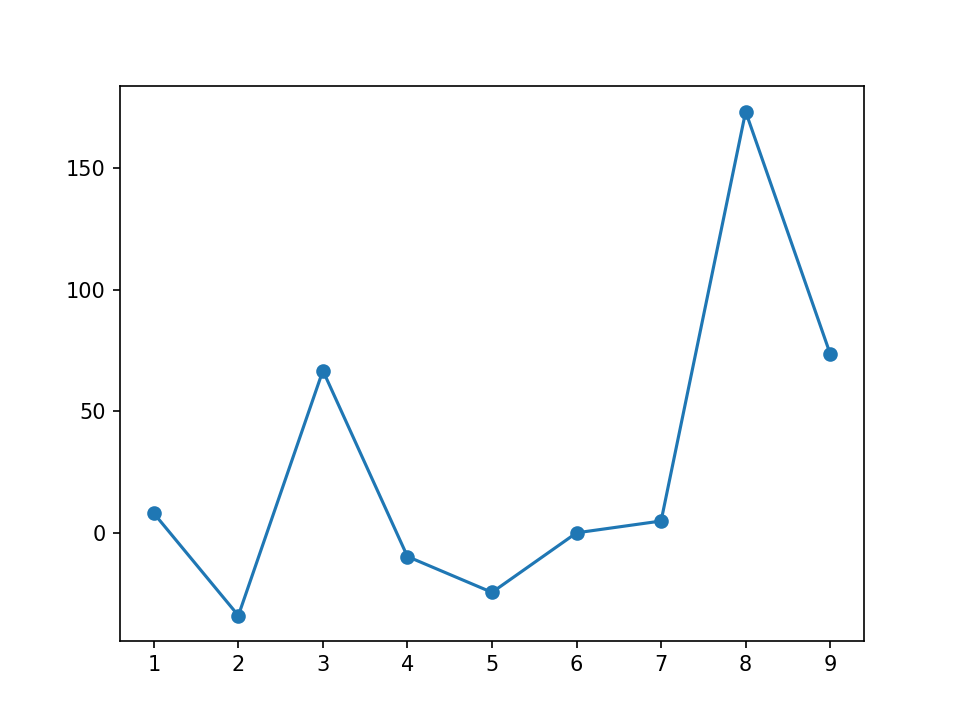
棒棒糖图§
import matplotlib.pyplot as plt import pandas as pd import numpy as np df = pd.DataFrame({'group': list(map(chr, range(65, 85))), 'values': np.random.uniform(size=20) }) ordered_df = df.sort_values(by='values') my_range = range(1, len(df.index)+1) plt.stem(ordered_df['values']) plt.xticks(my_range, ordered_df['group']) plt.show()棒棒糖图其实就是柱状图的变形,显示一个线段和一个圆。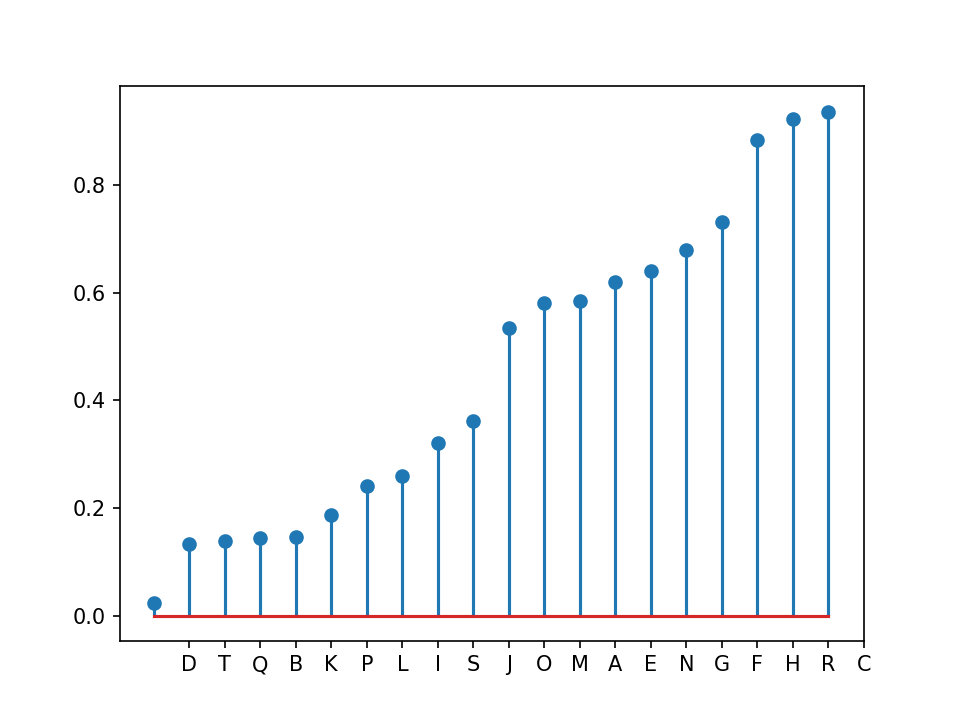
饼图§
import matplotlib.pyplot as plt size_of_groups = [12, 11, 3, 30] plt.pie(size_of_groups) plt.show()饼图,最常见的可视化图表之一。 将圆划分成一个个扇形区域,每个区域代表在整体中所占的比例。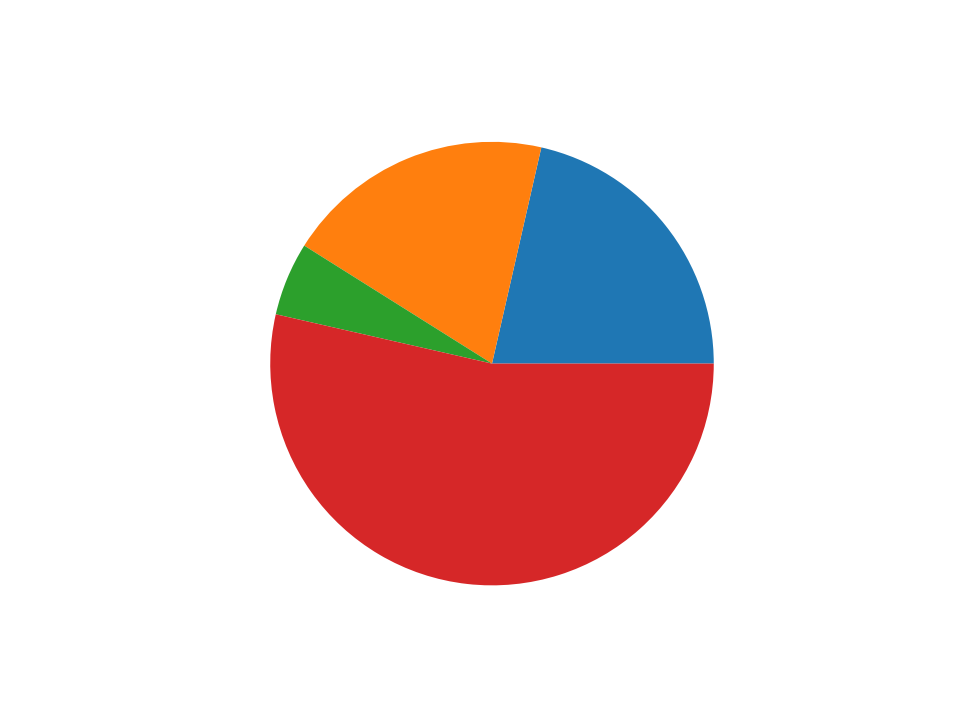
圆环图§
import matplotlib.pyplot as plt size_of_groups = [12, 11, 3, 30] plt.pie(size_of_groups) my_circle = plt.Circle((0, 0), 0.7, color='white') p = plt.gcf() p.gca().add_artist(my_circle) plt.show()圆环图,本质上就是一个饼图,中间切掉了一个区域。
面积图§
import matplotlib.pyplot as plt x = range(1, 6) y = [1, 4, 6, 8, 4] plt.fill_between(x, y) plt.show()面积图和折线图非常相似,区别在于和x坐标轴间是否被颜色填充。
堆叠面积图§
import matplotlib.pyplot as plt x = range(1, 6) y1 = [1, 4, 6, 8, 9] y2 = [2, 2, 7, 10, 12] y3 = [2, 8, 5, 10, 6] plt.stackplot(x, y1, y2, y3, labels=['A', 'B', 'C']) plt.legend(loc='upper left') plt.show()堆叠面积图表示若干个数值变量的数值演变。 每个显示在彼此的顶部,易于读取总数,但较难准确读取每个的值。
核密度估计图§
import seaborn as sns import matplotlib.pyplot as plt df = sns.load_dataset('iris') sns.kdeplot(df['sepal_width']) plt.show()核密度估计图其实是对直方图的一个自然拓展。 可以可视化一个或多个组的数值变量的分布,非常适合大型数据集。
箱形图§
import seaborn as sns import matplotlib.pyplot as plt df = sns.load_dataset('iris') sns.boxplot(x=df["species"], y=df["sepal_length"]) plt.show()箱形图,可视化一组或多组数据的分布情况。 可以快速获得中位数、四分位数和异常值,但也隐藏数据集的各个数据点。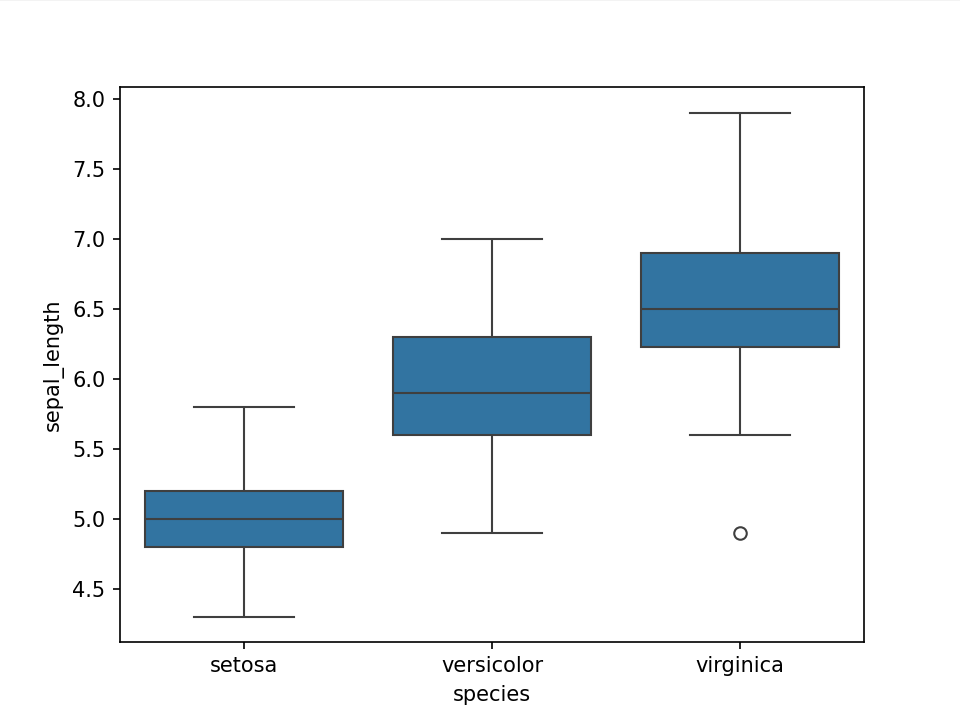
小提琴图§
import seaborn as sns import matplotlib.pyplot as plt df = sns.load_dataset('iris') sns.violinplot(x=df["species"], y=df["sepal_length"]) plt.show()小提琴图可以将一组或多组数据的数值变量分布可视化。 相比有时会隐藏数据特征的箱形图相比,小提琴图值得更多关注。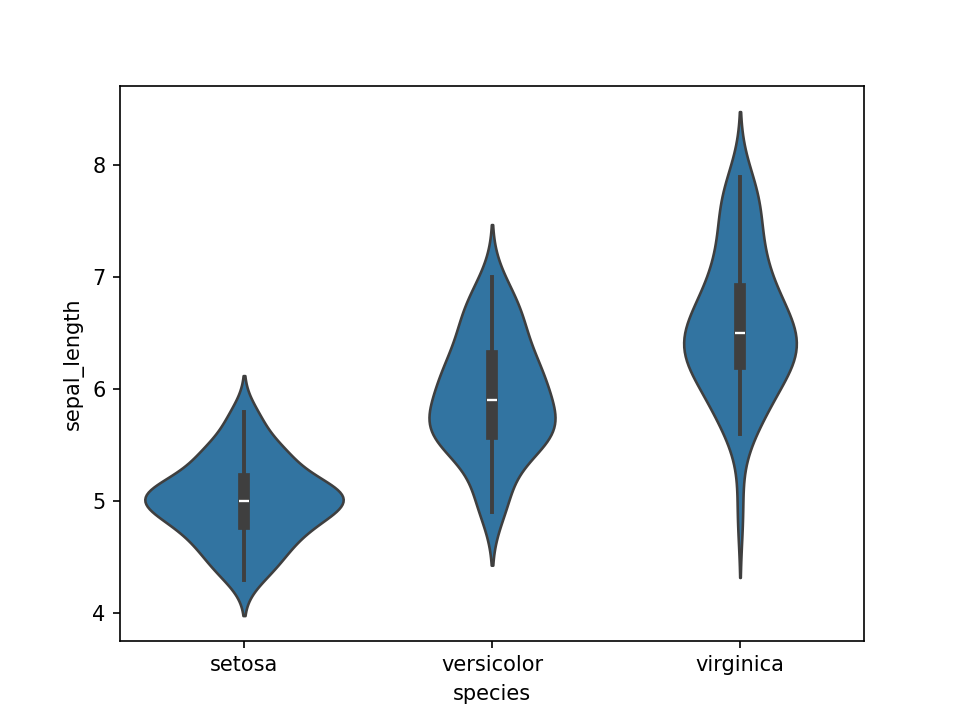
平行座标图§
import seaborn as sns import matplotlib.pyplot as plt from pandas.plotting import parallel_coordinates data = sns.load_dataset('iris', data_home='seaborn-data', cache=True) parallel_coordinates(data, 'species', colormap=plt.get_cmap("Set2")) plt.show()一个平行座标图,能够比较不同系列相同属性的数值情况。 Pandas可能是绘制平行坐标图的最佳方式。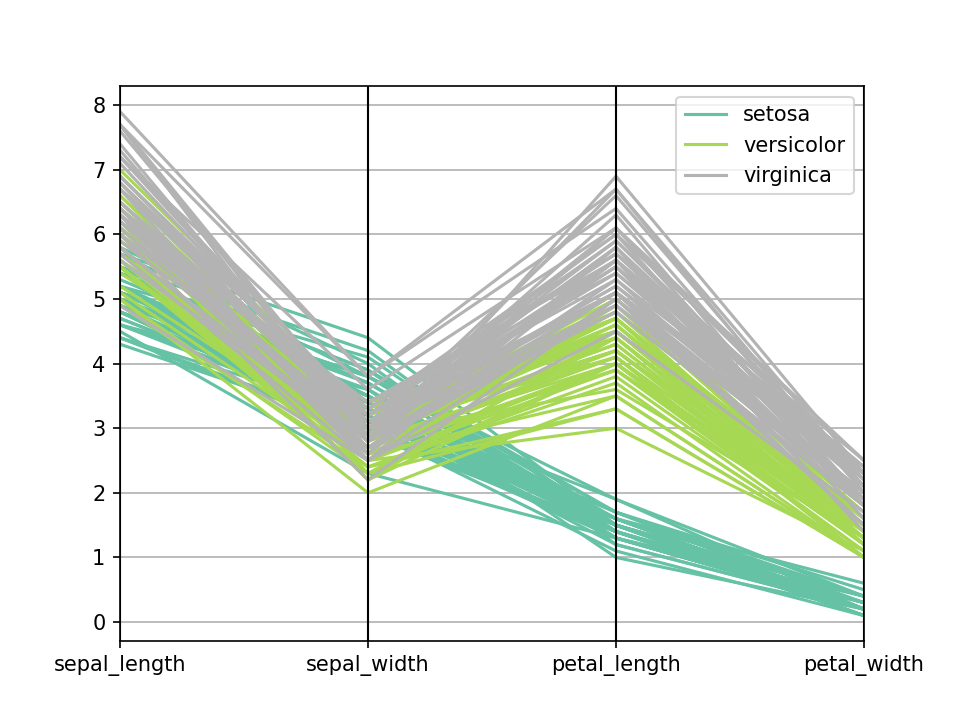
气泡图§
import matplotlib.pyplot as plt import seaborn as sns from gapminder import gapminder data = gapminder.loc[gapminder.year == 2007] sns.scatterplot(data=data, x="gdpPercap", y="lifeExp", size="pop", legend=False, sizes=(20, 2000)) plt.show()气泡图其实就是一个散点图,其中圆圈大小被映射到第三数值变量的值。图表示每个变量的分布。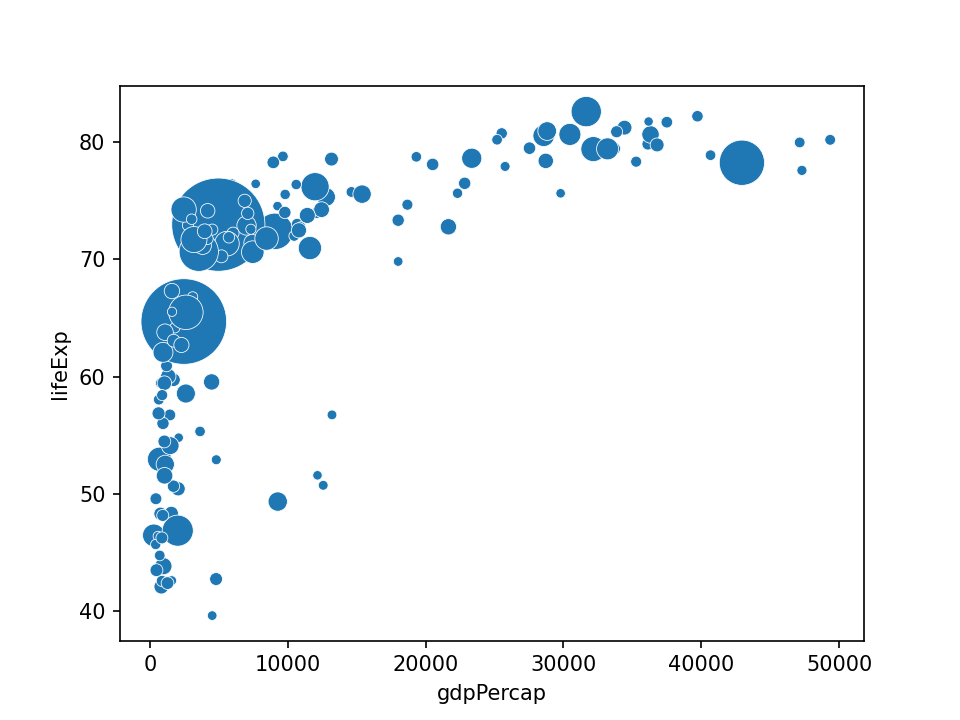
矩形热力图§
import seaborn as sns import matplotlib.pyplot as plt import pandas as pd import numpy as np df = pd.DataFrame(np.random.random((5,5)), columns=["a","b","c","d","e"]) sns.heatmap(df) plt.show()矩形热力图,矩阵中的每个值都被表示为一个颜色数据。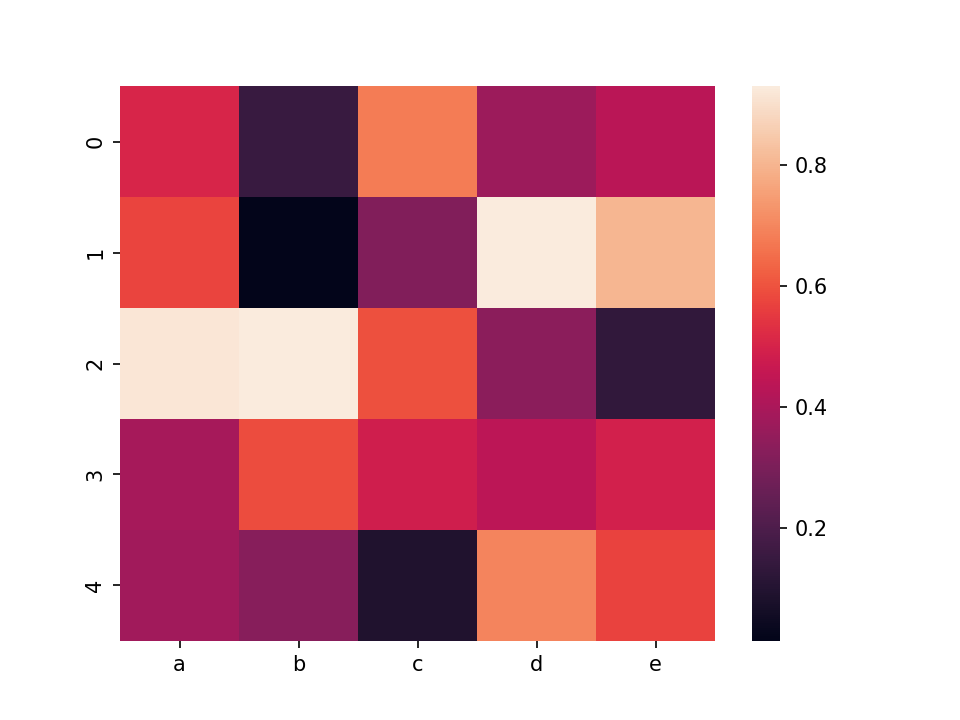
二维密度图§
import numpy as np import matplotlib.pyplot as plt from scipy.stats import kde data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) x, y = data.T fig, axes = plt.subplots(ncols=3, nrows=2, figsize=(25, 10)) axes[0][0].set_title('Scatterplot') axes[0][0].plot(x, y, 'ko') nbins = 20 axes[0][1].set_title('Hexbin') axes[0][1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) axes[0][2].set_title('2D Histogram') axes[0][2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) k = kde.gaussian_kde(data.T) xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] zi = k(np.vstack([xi.flatten(), yi.flatten()])) axes[1][0].set_title('Calculate Gaussian KDE') axes[1][0].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) axes[1][1].set_title('2D Density with shading') axes[1][1].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[1][2].set_title('Contour') axes[1][2].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[1][2].contour(xi, yi, zi.reshape(xi.shape)) plt.show()二维密度图或二维直方图,可视化两个定量变量的组合分布。 它们总是在X轴上表示一个变量,另一个在Y轴上,就像散点图。 然后计算二维空间特定区域内的次数,并用颜色渐变表示。 形状变化:六边形a hexbin chart,正方形a 2d histogram,核密度2d density plots或contour plots。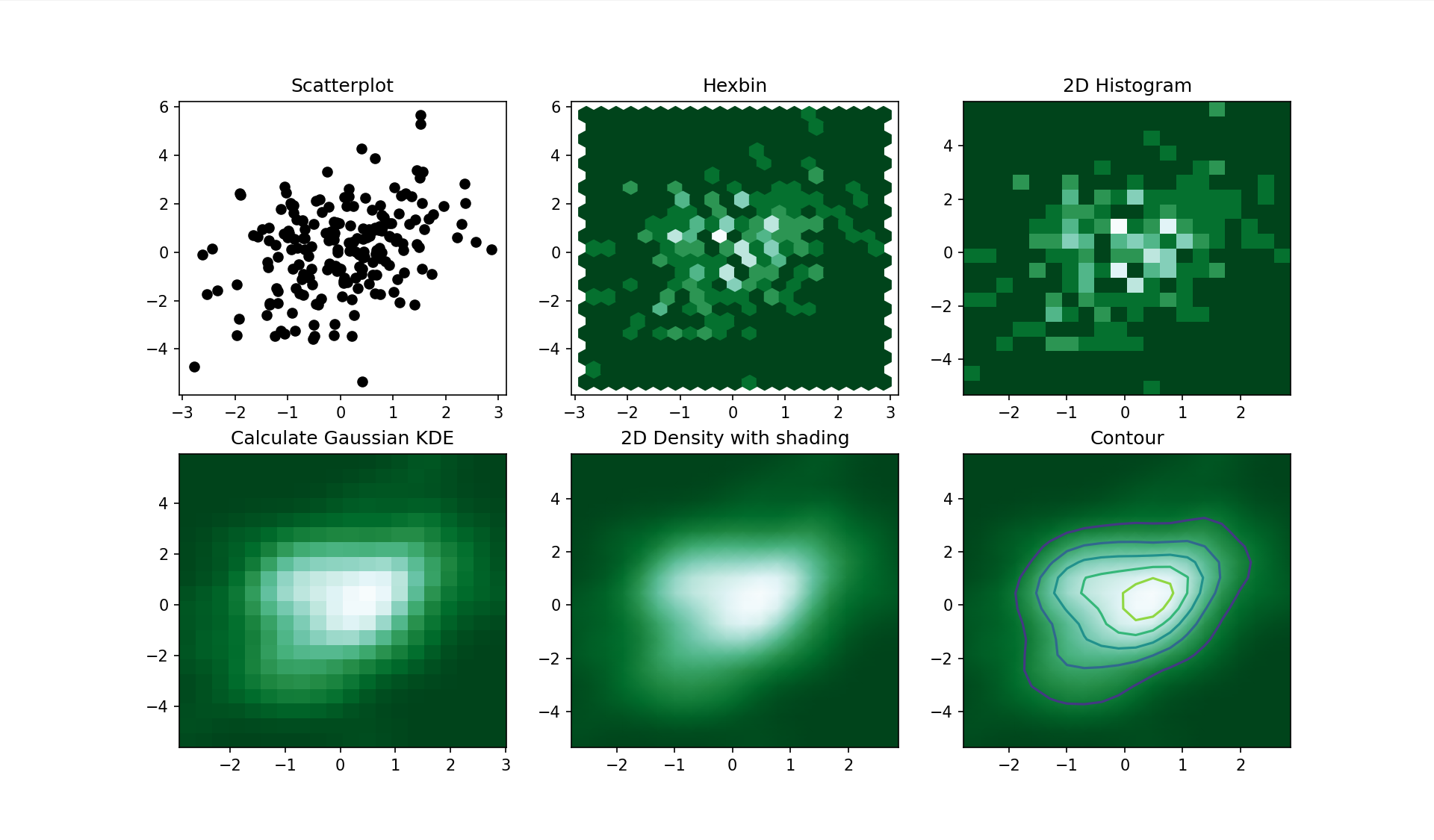
词云图§
from wordcloud import WordCloud import matplotlib.pyplot as plt text=("Python Python Python Matplotlib Chart Wordcloud Boxplot") wordcloud = WordCloud(width=480, height=480, margin=0).generate(text) plt.imshow(wordcloud, interpolation='bilinear') plt.axis("off") plt.margins(x=0, y=0) plt.show()词云图是文本数据的视觉表示。 单词通常是单个的,每个单词的重要性以字体大小或颜色表示。
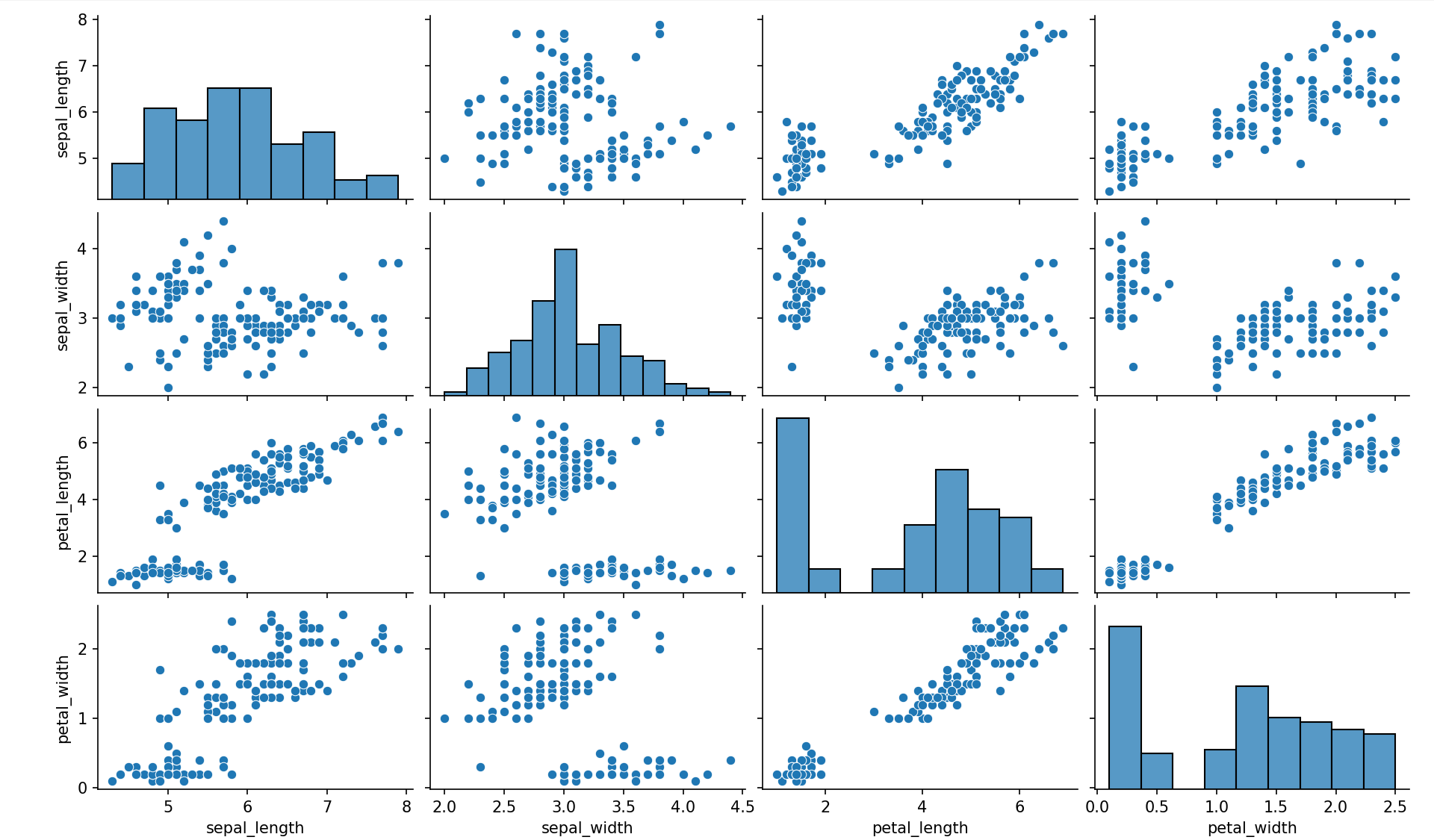
相关性图§
import seaborn as sns import matplotlib.pyplot as plt df = sns.load_dataset('iris') sns.pairplot(df) plt.show()相关性图或相关矩阵图,分析每对数据变量之间的关系。 相关性可视化为散点图,对角线用直方图或密度图表示每个变量的分布。